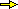 dipendenza e indipendenza
stocastica.
dipendenza e indipendenza
stocastica. Approfondiamo lo studio dei rapporti tra variabili casuali,
già avviato introducendo i concetti di
dipendenza e indipendenza
stocastica.
 Esempio 1
Esempio 1
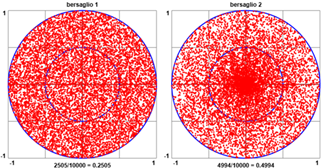
Due tipi di cadute a caso di proiettili in un bersaglio.
Vogliamo stimare sperimentalmente la probabilità che, prendendo "a caso" un
punto in un bersaglio composto da due cerchi concentrici con raggi uno doppio dell'altro, il punto
cada nel cerchio centrale. Consideriamo due possibili procedimenti, di cui puoi esaminare una versione
come "script"
(bersagl1.htm e
bersagl2.htm generano i punti e
calcolano le frequenze),
mediante i quali viene generato un punto che cade nel cerchio di centro O=(0,0) e raggio 1 e
verificato se la sua distanza da O è minore di 1/2, ovvero se il quadrato di essa è
minore di 0.25; gli script stampano la percentuale dei punti che cadono nel cerchio piccolo.
Qui sotto sono riprodotti le parti dei due script con il contenuto del ciclo (le variabili
lanci e ok contano una i lanci, l'altra quelli per i quali viene centrato il cerchio piccolo).
x=random()*2-1; y=random()*2-1;
if (x*x+y*y<1) {lanci=lanci+1; if (x*x+y*y < 0.25) {ok=ok+1};
r=random(); a=random()*PI*2; x=r*cos(a); y=r*sin(a);
lanci=lanci+1; if(x*x+y*y < 0.25) {ok=ok+1}; |
Se provi ad eseguire i due script ottieni, rispettivamente, uscite simili alle seguenti:
N=1e1→ 10%, N=1e2→ 23%, N=1e3→ 24.4%, N=1e4→ 25.01%, N=1e5→ 25.018%, N=1e6→ 25.014%, N=1e7→ 24.99786%
N=1e1→ 60%, N=1e2→ 51%, N=1e3→ 50.6%, N=1e4→ 50.63%, N=1e5→ 49.981%, N=1e6→ 50.0318%, N=1e7→ 49.97802%
Le figure seguenti riproducono la rappresentazione grafica di possibili uscite dei due procedimenti, ottenute con questo e quest'altro script (sotto ai grafici viene riportato il rapporto tra il numero dei punti che cadono nel cerchio piccolo e il totale dei punti.
I due procedimenti generano i punti in modo diverso: mentre il primo usa
il generatore di numeri casuali per ottenere un punto nel quadrato
Mentre col primo i proiettili si distribuiscono in modo uniforme nel cerchio, col secondo si distribuiscono concentrandosi maggiormente intorno a (0,0). Mentre col primo la frequenza tende a stabilizzarsi su 1/4, pari al rapporto tra area del centro e area del bersaglio, col secondo tende a stabilizzarsi su 1/2: il fatto che il punto generati disti meno di metà raggio dal centro dipende solo dal valore di r, che essendo con distribuzione uniforme in [0,1), ha il 50% di probabilità di essere minore di 1/2.
Si tratta di due cadute casuali con diverse leggi di distribuzione.
Qui stiamo estendendo il concetto di legge di distribuzione dal caso di una variabile casuale U a valori numerici al caso di U = (X,Y) con X e Y variabili casuali a valori in
Esempio 2
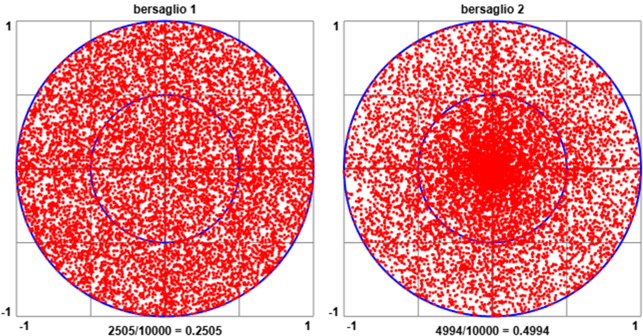
La tabella seguente rappresenta la distribuzione delle variabili Sesso e Settore di attività (classificato in "agricoltura", "industria", "altre attività") in cui una persona (in Italia nel 2012) era occupata:
per ogni possibile coppia
Una tabella "a doppia entrata" come questa, in cui sono indicate le frequenze o le probabilità di due variabili casuali viene detta tabella di contingenza
(se ne è già fatto
uso alla voce dipendenza e indipendenza). Il grafico al centro è l'istogramma tridimensionale che rappresenta la tabella; quello a destra è relativo a 20 anni prima, ad evidenziare come è cambiata la distribuzione (nei servizi la percentuale di donne occupate ha superato quella dei maschi; sono molto diminuiti gli occupati in agricoltura; e, come si capisce considerando la somma delle colonne dei maschi e quella delle colonne delle femmine, è decisamente aumentata l'occupazione delle donne). La tabella successiva
riporta (relativamente al 2012) anche i totali delle righe e delle colonne.
(*1000) Maschi Femmine Agricoltura 603 246 (anno 2012) Industria 5051 1311 Servizi 7787 7901
Maschi Femmine Totale
Agricoltura 603 246 849
Industria 5051 1311 6362
Servizi 7787 7901 15688
Totale 13441 9458 22899
|
 |
Gli istogrammi tridimensionali come i precedenti non sono facili da realizzare: occorre, per esempio, cambiare l'orientamento per visualizzare bene tutte le colonne. È facile invece calcolare le percentuali e realizzare gli istogrammi riga per riga o colonna per colonna:
| Distribuzione % delle colonne | 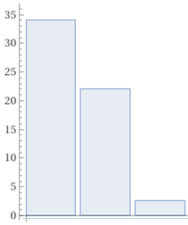
34%, 22.1%, 2.6% S I A maschi | 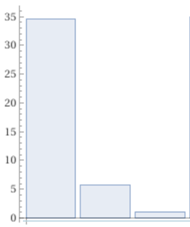 34.5%, 5.7%, 1.1% S I A femmine |
| Distribuzione % delle righe | 
2.6%, 1.1% M F agricoltura | 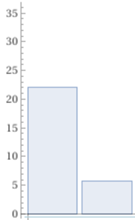
22.1%, 5.7% M F industria | 
34%, 34.5% M F servizi |
Vediamo i comandi con cui sono state ottenute le rappresentazioni precedenti con WolframAlpha:
603+5051+7787+246+1311+7901 -> 22899 totale round {7787/T*100, 5051/T*100, 603/T*100}, 0.1 where T = 22899 distribuzione % maschi arrotondata ai decimi round {7901/T*100, 1311/T*100, 246/T*100}, 0.1 where T = 22899 distribuzione % femmine arrotondata ai decimi Bar Chart(7787/T*100, 5051/T*100, 603/T*100, 0, 35) where T = 22899 <- vedi sotto le spiegazioni Bar Chart(7901/T*100, 1311/T*100, 246/T*100, 0, 35) where T = 22899
| Per realizzare gli istogrammi usiamo il comando Bar Chart (grafici a barre) in cui inseriamo le percentuali. Per confrontare più istogrammi ci conviene farli di eguale altezza, ad esempio 35 (per cento). Allora aggiungiamo in entrambi i casi
i dati 0 (per fare una colonna vuota) e 35 (per fare una colonna altra 35). Poi copiamo e incolliamo nel documento solo le prime tre colonne dell'istogramma, come illustrato qui a destra. In modo analogo calcoliamo le percentuali e realizziamo gli istogrammi relativi alle righe della tabella: |  |
round {603/T*100, 246/T*100}, 0.1 where T = 22899 distribuzione % agricoltura arrotondata ai decimi
round {5051/T*100, 1311/T*100}, 0.1 where T = 22899 distribuzione % industria arrotondata ai decimi
round {7787/T*100, 7901/T*100}, 0.1 where T = 22899 distribuzione % servizi arrotondata ai decimi
Bar Chart(603/T*100, 246/T*100, 0, 35) where T = 22899
Bar Chart(5051/T*100, 1311/T*100, 0, 35) where T = 22899
Bar Chart(7787/T*100, 7901/T*100, 0, 35) where T = 22899
In tabella:
Maschi Femmine Totale
Agricoltura 2.6% 1.1% 3.7%
Industria 22.1% 5.7% 27.8%
Servizi 34% 34.5% 68.5%
Totale 58.7% 41.3% 100%
|
Facendo riferimento ai totali delle righe e delle colonne possiamo calcolare le cosiddette distribuzioni marginali:

round {849/T*100, 6362/T*100, 15688/T*100}, 0.1 where T = 22899 -> 3.7, 27.8, 68.5
round {13441/T*100, 9458/T*100}, 0.1 where T = 22899 -> 58.7, 41.3
Un altro termine usato è "profili":

round {603/T*100, 5051/T*100, 7787/T*100},0.1 where T=7787+5051+603 -> 4.5, 37.6, 57.9
round {246/T*100, 1311/T*100, 7901/T*100},0.1 where T=7901+1311+246 -> 2.6, 13.9, 83.5
round {603/T*100, 246/T*100},0.1 where T = 603+246 -> 71, 29
round {5051/T*100, 1311/T*100},0.1 where T = 5051+1311 -> 49.6, 50.4
round {7787/T*100, 7901/T*100},0.1 where T = 7787+7901 -> 79.4, 20.6
Rappresentazione grafica delle leggi di distribuzione
Nel caso di una singola variabile a valori in un intervallo di numeri reali realizzavamo un istogramma classificando
le uscite in intervallini; analogamente, nel nuovo caso, possiamo rappresentare le distribuzioni classificando le uscite
in tanti rettangolini.
Sotto è rappresentata la legge di distribuzione di
Nel caso dell'esempio iniziale, la caduta dei proiettili, siamo di fronte a un sistema (X,Y) di variabili casuali non discrete. Un'idea della distribuzione mi è fornita dal grafico di dispersione (scatter diagram), ossia dalla rappresentazione grafica delle coppie di uscite sperimentali, già visto e qui riprodotto:
Per una rappresentazione tridimensionale osserviamo che, come nel caso di una singola variabile variabile continua X a valori in un intervallo
di numeri reali realizzavamo un istogramma classificando le uscite in intervallini che, all'infittirsi della partizione, tendeva a stabilizzarsi su una curva, ora
possiamo rappresentare
le distribuzioni classificando le uscite in tanti rettangolini la cui unione copra il dominio delle uscite.
Se all'aumentare delle prove e all'infittirsi dei rettangolini
il contorno superiore dell'istogramma tridimensionale (in cui ogni colonnina abbia altezza pari alla frequenza relativa divisa
per l'area del rettangolino di base, in modo che il volume complessivo sia 1) tende a stabilizzarsi su una superficie che
sottende uno spazio di volume 1, il calcolo delle
probabilità può essere ricondotto al calcolo di volumi.
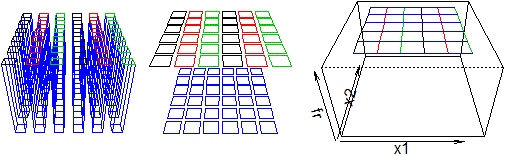
Nel caso del "primo bersaglio" l'istogramma tende ad essere una superficie piatta, analogamente a quanto accadeva per il lancio di due
dadi equi. In questo caso tende ad essere la base superiore di un cilindro con area di base π (cerchio di raggio 1) e altezza 1/π = 0.318309…
Vedi la figura sottostante a sinistra.
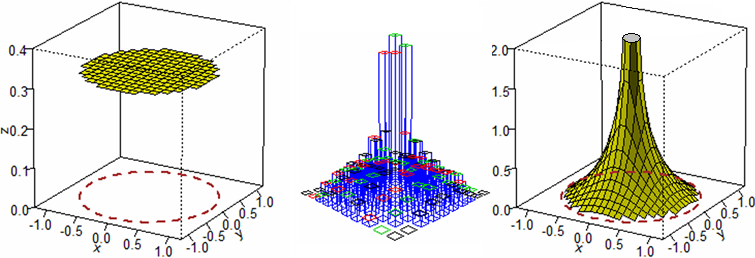
Sopra al centro una possibile rappresentazione per il secondo tipo di cadute (in cui, come nel caso del lancio di due dadi, le colonnine sono state separate per facilitare la "lettura"). A destra la corrispondente superficie a cui tende l'istogramma all'aumentare del numero delle prove.
È una superficie illimitata (che abbiamo tagliato alla quota z=2) che, comunque, racchiude col piano xy uno spazio di volume 1.
Analogamente al caso univariato,
le funzioni di due variabili sul cui grafico tendono a stabilizzarsi gli istogrammi sperimentali
si chiamano funzioni di densità. Su come rappresentare graficamente le funzioni di due variabili ci si sofferemerà nella
voce lo spazio 3D (2).
Osserviamo che, come abbiamo già visto che una
superficie illimitata può avere area finita (
leggi di distrib. var. discrete),
così un solido illimitato può avere volume finito.
|
Le curve di livello sono cerchi concentrici.
Il volume è 1, per cui il cono deve essere alto 3/π: questo è |
 |
Dipendenza / indipendenza
Come si fa a capire dal grafico della distribuzione di U=(X,Y) se X e Y sono variabili casuali indipendenti o no?
Nel caso  dell'istogramma di (Sesso,Settore) la riga di colonne che rappresenta la distribuzione dei maschi non ha andamento analogo a quella delle femmine,
e questo ci fa capire che Sesso e Settore non sono indipendenti.
Nel caso del lancio di due dadi, invece, tutte le righe di colonne hanno andamento simile (anzi, uguale):
le uscite di primo e secondo dado sono indipendenti.
L'ipotesi di indipendenza corrisponde, nel caso finito (e nel caso sperimentale), alla proporzionalità tra le righe o
tra le colonne della tabella a doppia entrata e, passando all'istogramma tridimensionale, corrisponde alla proporzionalità
tra le altezze delle righe di colonnine o tra le altezze delle file di colonnine.
dell'istogramma di (Sesso,Settore) la riga di colonne che rappresenta la distribuzione dei maschi non ha andamento analogo a quella delle femmine,
e questo ci fa capire che Sesso e Settore non sono indipendenti.
Nel caso del lancio di due dadi, invece, tutte le righe di colonne hanno andamento simile (anzi, uguale):
le uscite di primo e secondo dado sono indipendenti.
L'ipotesi di indipendenza corrisponde, nel caso finito (e nel caso sperimentale), alla proporzionalità tra le righe o
tra le colonne della tabella a doppia entrata e, passando all'istogramma tridimensionale, corrisponde alla proporzionalità
tra le altezze delle righe di colonnine o tra le altezze delle file di colonnine.
In generale, passando alle funzioni di densità al posto delle righe e delle file di colonnine si considerano le sezioni parallele al piano xz e le sezioni parellele al piano yz: due qualunque sezioni, ad esempio parallele al piano xz, devono essere ottenibili una dall'altra mediante una dilatazione/contrazione verticale. Nel caso delle funzioni densità dei due esempi inziali, dei proettili, ciò non accade mai: ad esempio la sezione determinata dal piano yz non ha lo stesso andamento (a meno di un fattore di scala) di nessuna delle altre sezioni ad essa parallela. Del resto è intuitivo che il valore di X e quello di Y sono tra loro condizionati: devono essere le coordinate di un punto che sta nel cerchio (X²+Y² deve essere al più 1; se X è vicino ad 1 Y per forza deve essere vicino a 0).
Nel caso del sistema di variabili avente densità che ha per grafico un cono circolare retto,
considerato sopra, X e Y sono indipendenti?
Evidentemente no, per le stesse motivazioni usate per le altre densità appena considerate.
Altri due esempi. A destra è rappresentato un sistema (X,Y) con X e Y indipendenti. Comunque sezioni la superficie con piani paralleli ai piani xz e yz ottengo grafici con andamenti simili: hanno massimo e punto di flesso collocati nella stessa posizione. Potrebbe avere una forma simile (anche se non centrata in (0,0) e con diverse unità su gli assi) la distribuzione di (X,Y) con X e Y altezze di un uomo e una donna sorteggiati a caso. Invece, nel caso della superficie sotto a sinistra (per la quale a destra abbiamo tracciato un possibile grafico di dispersione sperimentale) siamo di fronte a X e Y non indipendenti; ad es., è evidente che le sezioni parallele al piano yz sono curve con il punto di massimo che man mano si sposta verso destra (avanza lungo la direzione dell'asse y). | 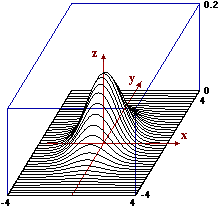 |
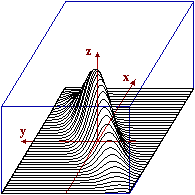

Potrebbe avere una forma simile la distribuzione di (X,Y) con X e Y altezze di marito e moglie di una coppia sorteggiata a caso: l'altezza di uomini spostati con donne di una certa altezza ha andamento più o meno gaussiano, ma la loro altezza media è maggiore di quella degli uomini sposati con donne più basse (uomini più alti tendenzialmente sposano donne più alte: non è affatto vero che l'amore è cieco!).
Ma la dipendenza tra X e Y in questo ultimo caso è in un qualche senso "più forte" di quella che c'era tra X e Y nel caso dei proiettili: là avevamo che i valori che poteva assumere una delle due variabili era condizionato da quello che assumeva l'altra, qui abbiamo qualcosa di più: al crescere di X anche Y tende a crescere. Su questo aspetto ci si sofferma nella successiva voce "correlazione".
Sotto sono tracciate alcune curve di livello delle due ultimi superfici considerate. Nel primo caso sono ellissi simmetriche rispetto agli assi x e y, nel secondo hanno assi di simmetria obliqui, a conferma del fatto che al crescere dell'uscita X l'uscita di Y tende a crescere anch'essa.
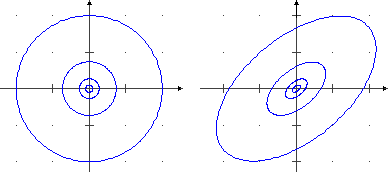
Esercizi: Uno e
soluzione
Due e
soluzione
Approfondimenti: cenni alla sistemazione formale
Vediamo, a grandi linee, come precisare le considerazioni precedenti.
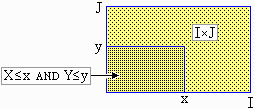
Consideriamo U = (X ,Y) con X e Y variabili casuali a valori in R. Siano X e Y a valori negli intervalli, rispettivamente, I e J. U ha valori in I×J.
La legge di distribuzione di U è nota quando so calcolare i valori di una misura di probabilità Pr su tutti gli eventi del tipo U∈E×F con E e F sottointervalli di I e J: Pr(U∈E×F) = Pr(X∈E and Y∈F). Con la additività posso poi valutare Pr(U∈D) per altri domini D (cioè per altri insiemi ottenibili come "unioni numerabili di rettangolini").
I punti in cui cadono i
proettili considerati nell'esempio iniziale sono esempi di variabili bidimensionali a valori in domini non rettangolari, ma può convenire considerarle definite in un rettangolo I×J, [−1,1]×[−1,1] o tutto R²: invece di considerare U a valori nel cerchio C posso considerare V tale che Pr(V∈E) =Pr(U∈E) se E è contenuto in C, Pr(V∈E)=0 se E è esterno a C.
|
La funzione di ripartizione f sarà: Se X e Y sono indipendenti, Pr(U∈E×F) = Pr(X∈E)·Pr(Y∈F) e f(x,y) = f1(x)·f2(y) (se f1 e f2 sono le funzioni di ripartizione di X e Y). |
 |
Nel caso discreto (X e Y variabili discrete) la legge di distribuzione è
nota se so calcolare i valori della misura di probabilità Pr su tutti gli eventi del tipo
U =
In tal caso la legge di distribuzione è rappresentabile con un istogramma tridimensionale, come quello raffigurato all'inizio del
paragrafo precedente, a sinistra.
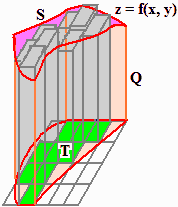
Per estendere la definizione di probabilità al caso continuo dobbiamo estendere il concetto di integrale al caso bivariato.
Se f è una funzione positiva di due variabili definita su una superficie piana T che è continua, ossia,
intuitivamente, che ha per grafico una superficie S di R³
senza tagli, ovvero che è tale che all'avvicinarsi di (x,y) ad un punto P L'integrale di f su T viene indicato con la notazione ∫∫T f. |
 |
|
Così come, nel caso univariato, abbiamo visto che (all'aumentare delle prove e all'infittirsi della partizione) l'istogramma sperimentale di una variabile continua U tende a stabilizzarsi sul grafico di una funzione f tale che Pr(c≤U≤d) è pari all'integrale di f tra c e d, così chiameremo continua una variabile bidimensionale per cui esista una funzione a 2 input f (funzione di densità) tale che, per ogni evento del tipo U∈E×F con E e F sottointervalli di I e J (se U varia in I×J): |
| |||
|
La superficie grafico di f approssima gli istogrammi sperimentali. Il volume del cilindro verticale avente per base il dominio T e limitato superiormente dal grafico di f è Pr(U∈T). Ovviamente: |
|
Si ha che X e Y (continue) sono indipendenti sse f(x,y) = f1(x) f2(y), dove f1 e f2 sono le funzioni di densità di X e Y. In altre parole, le sezioni con piani y=k sono tra loro scalate verticalmente (f(x,k) = f1(x) f2(k)) e una cosa analoga accade per le sezioni con piani x=k. Nel caso discreto, si ha un istogramma tridimensionale le cui righe [colonne] di parallelepipedi sono istogrammi (bidimensionali) che sarebbero tra loro uguali se normalizzati.
Ciò traduce il fatto che comunque fissi X [Y], la variabile Y [X] si distribuisce sempre allo stesso modo, senza subire influenze.
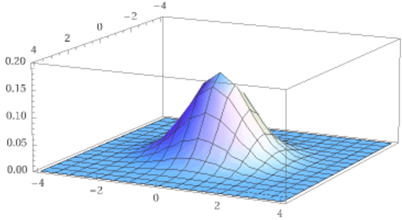
Nel paragrafo precedente il primo grafico riprodotto è della funzione di densità di U=(X,Y)
dove X e Y hanno densità gaussiana di media 0 e s.q.m. 1 e sono indipendenti. Le curve di livello sono cerchi con centro (0,0).
Comunque sezioni con piani paralleli ai piani xz e yz ottengo grafici ottenibili scalando verticalmente la gaussia di s.q.m. 1 e media 0. Le funzioni densità sono:
2 2 2 2
x +y x y
- ————— - ——— - ———
1 2 1 2 1 2
f(x,y) = ——— e f1 (x) = ————— e f2 (y) = ————— e
2π √(2π) √(2π) |
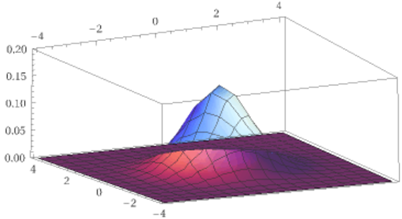
3D plot z = exp(-(x^2+y^2)/2)/(2*pi), x=-4..4, y=-4..4, z=0..0.2 view from (8,4,2)
3D plot z = exp(-(x^2+y^2)/2)/(2*pi), x=-4..4, y=-4..4, z=0..0.2 view from (8,4,0.2)
3D plot z = exp(-(x^2+y^2)/2)/(2*pi), x=-4..4, y=-4..4, z=0..0.2 view from (8,4,-2)
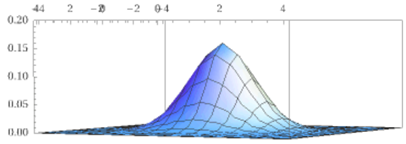
Anche la seconda funzione rappresentata graficamente nel precedente paragrafo è la densità di U=(X,Y) con X e Y aventi densità gaussiana di media 0 e s.q.m. 1, ma in questo caso X e Y non sono indipendenti; ad es., è evidente che le sezioni parallele al piano yz sono curve con il punto di massimo che man mano si sposta verso destra (avanza lungo la direzione dell'asse y). Le curve di livello in questo caso particolare sono ellissi aventi le bisettrici dei quadranti come assi di simmetria.
Gli integrali di funzioni di due variabili possono essere affrontati facilmente con WolframAlpha: per calcolare l'integrale per x ed y tra −∞ e ∞ della prima delle funzioni precedenti basta battere:
integrate 1/(2*pi)*exp(-(x^2+y^2)/2) dx dy, x=-inf..inf, y=-inf..inf
Che cosa ottengo se batto quanto segue?:
sqrt(integrate 1/(2*pi)*exp(-(x^2+y^2)/2) dx dy, x=-1..1, y=-1..1)
Che cosa se batto quanto segue?:
integrate 1 dx dy, x=-1..1, y=-1..1